
ZIP_PATH = DATA_DIR / "Urban.zip"
# Parse wavelengths from the .wvl file (tab-separated, \r line endings, col 1 = nm)
with zipfile.ZipFile(ZIP_PATH) as zf:
wvl_name = next(n for n in zf.namelist() if n.endswith(".wvl"))
with zf.open(wvl_name) as f:
lines = f.read().decode("ascii").replace("\r", "\n").splitlines()
wavelengths = np.array([float(l.split("\t")[1]) for l in lines if l.strip()])
# The .hdr is a custom HyperCube format, not standard ENVI, so we read the binary directly.
# Header specifies: big-endian int16, BIL interleave, 307 samples x 307 lines x 210 bands.
with zipfile.ZipFile(ZIP_PATH) as zf:
data_name = next(n for n in zf.namelist() if not n.endswith(("/", ".hdr", ".wvl")))
with zf.open(data_name) as f:
raw = np.frombuffer(f.read(), dtype=np.dtype(">i2"))
H, W, B = 307, 307, 210
cube = raw.reshape(H, B, W).transpose(1, 0, 2) # BIL: lines x bands x samples -> bands x rows x cols
print(f"Cube shape: {cube.shape}")
print(f"Wavelength range: {wavelengths[0]:.0f} - {wavelengths[-1]:.0f} nm")
print(f"Dtype: {cube.dtype}, Min: {cube.min()}, Max: {cube.max()}")The question
This post came out of a gap in my own understanding. I knew what hyperspectral imagery was useful for, but I did not yet feel fluent enough to open a cube from scratch and trust what I was seeing. So I worked from the data upward: load the scene, inspect a few spectra, and follow the methods until they stopped feeling opaque.
What follows is the guide I wanted at the start. It is not a full hyperspectral textbook. It is a way to get from “I know how to read satellite imagery and false-color composites” to “I understand what a hyperspectral pixel is, why people reshape cubes into matrices, and what PCA, unmixing, and NMF are actually doing.”
If you work with remote sensing imagery, you already know the usual move: choose a few bands, stretch them well, and interpret the resulting composite. Even a good false-color image, though, still compresses the scene down to a small number of broad spectral channels.
Hyperspectral imagery changes the question. Instead of 3 broad RGB bands, or even a modest multispectral stack, it records hundreds of narrow, contiguous wavelength channels. In the HYDICE Urban scene used here, each pixel carries a 210-value spectrum spanning the visible through the shortwave infrared.
That full spectral curve is what makes hyperspectral analysis different from standard image interpretation. Vegetation, asphalt, bare ground, rooftops, and metal surfaces can overlap in brightness or color in a broad-band composite while still differing strongly in spectral shape. The question stops being only “what does this object look like in a display image?” and becomes “what spectral signature is present in this pixel, and what does that imply about materials?”
So the real question in this post is: given a full spectrum at each pixel, can we separate the scene into meaningful material patterns without labels?
Note
How to read this post
- If you are new to the topic, the most important sections are Pixel spectra, From cube to matrix, and the intuition summaries inside each method.
- If you are comfortable with linear algebra, the displayed equations show the same ideas in matrix form.
- If you mainly want the practical judgment call, skip to What these methods are actually for near the end.
Three approaches, each with a different way of framing that problem:
- Principal component analysis (PCA): What are the dominant directions of spectral variance in the scene? PCA is the compression view. It asks how much of the 210-band signal can be summarized with a small number of orthogonal patterns.
- Linear spectral unmixing: If we already know what a few pure materials look like, what fraction of each material is present in a given pixel? This is the fraction view, closest to the classic subpixel remote-sensing problem.
- Non-negative matrix factorization (NMF): Can we learn additive, material-like spectral patterns directly from the data, without supplying endmembers ahead of time? This is the discovery view.
Tip
Remote-sensing intuition. A false-color composite asks: which three bands should I display? Hyperspectral analysis asks a different question: what can I learn if I use the entire spectral curve at each pixel instead of just a few display bands?
Note
Why a non-specialist might care. The broader idea here is not unique to remote sensing. Once every observation carries a long feature vector instead of one or two numbers, the job becomes: find the main directions of variation, estimate mixtures, or learn parts. The same logic shows up in chemistry, audio mixtures, genomics, and other high-dimensional signals.
Use PCA when you want the strongest spectral contrasts in the scene, whether or not they map cleanly onto physical materials. It is especially useful for compression, QA, dimensionality reduction, and anomaly screening.
Use linear unmixing when you already have plausible endmembers and want outputs that read like material fractions. This is the most direct fit to the remote-sensing question of mixed pixels and subpixel composition.
Use NMF when you want interpretable additive components but do not yet trust a fixed endmember library. It often sits between purely mathematical compression and fully supervised unmixing.
| Method | Main question | Matrix view | Easiest way to read the output |
|---|---|---|---|
| PCA | What varies most across the scene? | \(X_c \approx ZV^T\) | Contrast axes plus eigenimages |
| Unmixing | What is this pixel made of? | \(X \approx SM^T\) | Material fractions |
| NMF | What additive parts can I learn? | \(X \approx WH\) | Learned parts plus weight maps |
The data
We’ll use HYDICE Urban (U.S. Army Engineer Research and Development Center 2004), a classic hyperspectral benchmark from the U.S. Army Engineer Research and Development Center. It is a 307 x 307 pixel urban scene with 210 bands spanning roughly 400-2500 nm, at about 2 m ground sampling distance.
It is a useful teaching scene because it mixes vegetation, roads, rooftops, bare ground, and shadow in a compact area. If you already have intuition for urban false-color imagery, this dataset is a natural next step: the same scene elements are there, but now we can analyze their full spectral behavior rather than only a few displayed bands.
Note
Getting the data. Download the URBAN sample ZIP from the ERDC HyperCube page. Leave it zipped and place it at data/HYDICE_Urban/Urban.zip relative to this post, the loading code extracts it to a temporary directory automatically.
To run the code cells yourself, change eval: false to eval: true in the document YAML. All figures in this post were pre-generated and committed.
If you want a more widely used imaging-spectroscopy benchmark, the same ideas also apply to AVIRIS Moffett Field (Jet Propulsion Laboratory 1992), a 224-band scene over water, vegetation, and urban land near Mountain View, California. The workflow is almost the same; you mainly change the file path and, if needed, mask a few strong water-absorption bands.
Loading the cube
This is a sensor-native style product: a binary cube plus a few small metadata files. The main data file holds the radiance values, while the wavelength file tells us which wavelength corresponds to each band. If you have worked with ENVI-style remote-sensing products before, the layout will feel familiar.
The .wvl file is plain text, so we read it directly from the ZIP archive with Python’s zipfile module:
The cube shape (B, H, W) means:
- first index = wavelength band
- second index = row
- third index = column
That layout is convenient because it makes both views of the data easy: one band at a time as an image, or one pixel at a time as a spectrum.
Note
Simple mental picture. A hyperspectral cube is just a stack of grayscale images. Band 1 is the scene at one wavelength, band 2 is the same scene a few nanometers away, and so on. A pixel spectrum is what you get when you stop at one location and read straight down through that stack.
A note on radiance vs. reflectance
This dataset stores radiance, which is the light measured by the sensor. It does not store surface reflectance.
That distinction matters. Reflectance is usually easier to interpret as a surface property, because it is closer to “what fraction of incoming light did the target reflect?” Radiance still contains the material signal, but it also includes illumination geometry and atmospheric effects.
The relationship between the two is approximately:
\[\rho \approx \frac{\pi \, L \, d^2}{E_0 \cos(\theta_{SZ})}\]
where \(L\) is at-sensor radiance, \(E_0\) is top-of-atmosphere solar irradiance for that band, \(d\) is the Earth-Sun distance in AU, and \(\theta_{SZ}\) is the solar zenith angle (NASA Ocean Biology Processing Group 2023). Atmospheric-correction workflows go further than this simple relation and try to remove path radiance so the result is closer to true surface reflectance.
For this demo, radiance is fine. The decomposition math is the same either way. The main difference is interpretation: if you want to compare across dates, sensors, or spectral libraries, reflectance is the more physically stable quantity.
Important
Interpretation boundary. The outputs below are still useful on radiance, but they should not be read as scene-invariant material signatures. For library matching, cross-scene comparison, or retrieval tasks, surface reflectance is the safer input.
RGB composite
To make a normal-looking color image, we pick one band near red, one near green, and one near blue. Choosing them by wavelength instead of by hard-coded band number makes the code easier to reuse on other datasets:
Code
def nearest_band(wavelengths: np.ndarray, target_nm: float) -> int:
"""Return the band index closest to target_nm."""
return int(np.argmin(np.abs(wavelengths - target_nm)))
R = nearest_band(wavelengths, 650) # red
G = nearest_band(wavelengths, 550) # green
B_idx = nearest_band(wavelengths, 470) # blue
rgb = cube[[R, G, B_idx], :, :].astype(np.float32).transpose(1, 2, 0)
lo, hi = np.percentile(rgb, [2, 98])
rgb = np.clip((rgb - lo) / (hi - lo), 0, 1)
fig, ax = plt.subplots(figsize=(6, 6))
ax.imshow(rgb)
ax.set_title("HYDICE Urban: RGB composite (650 / 550 / 470 nm)", fontsize=11)
ax.axis("off")
plt.tight_layout()
plt.savefig(FIG_DIR / "rgb_composite.png", bbox_inches="tight")
plt.show()
Pixel spectra
A pixel spectrum is the basic object in hyperspectral analysis: one pixel, plotted across wavelength. If two surfaces are made of different materials, their spectral shapes often differ even when they look similar in a composite image.
Here are four hand-picked examples from recognizable surfaces in the RGB image:
Code
pixels = {
"Asphalt road": (200, 120),
"Grass lawn": (80, 200),
"Metal rooftop": (150, 50),
"Treed area": (50, 150),
}
fig, ax = plt.subplots(figsize=(8, 4))
for label, (row, col) in pixels.items():
spectrum = cube[:, row, col].astype(float)
ax.plot(wavelengths, spectrum, label=label, linewidth=1.5)
ax.set_xlabel("Wavelength (nm)")
ax.set_ylabel("Radiance (DN)")
ax.set_title("Example pixel spectra - HYDICE Urban")
ax.legend(frameon=False, fontsize=9)
plt.tight_layout()
plt.savefig(FIG_DIR / "pixel_spectra.png", bbox_inches="tight")
plt.show()![]()
Even without atmospheric correction, these curves separate cleanly. Grass shows the familiar vegetation red edge, low values in the red and a strong rise into the near-infrared. Asphalt is flatter. Rooftops are brighter and less vegetation-like. Those differences are exactly the signal the decomposition methods below try to isolate.
A few useful things to notice in that figure:
- vegetation curves are defined more by shape than by absolute brightness, especially around the red edge
- asphalt is relatively flat, so it tends to stand out less as a dramatic curve and more as a low-contrast baseline
- rooftops can be bright without looking vegetation-like, which is exactly why broad-band color alone is often not enough
From cube to matrix
All three methods below want the data in matrix form rather than cube form, so we flatten the image:
\[X \in \mathbb{R}^{N \times B}, \quad N = H \cdot W\]
Each row is one pixel spectrum. Each column is one wavelength band. We have not changed the data itself, only its shape.
If that still feels abstract, here is a tiny toy version. Imagine a 2 x 2 scene with four pixels:
\[ \text{Scene} = \begin{bmatrix} A:\ \text{road} & B:\ \text{grass} \\ C:\ \text{roof} & D:\ \text{trees} \end{bmatrix} \]
After flattening, the same scene becomes a pixel-by-band matrix:
\[ X_{\text{toy}} = \begin{bmatrix} 18 & 22 & 24 & 26 \\ 10 & 16 & 9 & 41 \\ 28 & 31 & 34 & 37 \\ 9 & 14 & 8 & 38 \end{bmatrix} \]
\[ \text{rows } = (A, B, C, D), \qquad \text{bands } = (450, 550, 650, 850)\ \text{nm} \]
Flattening turns image position into a row index. The spectrum in pixel \(B\) does not change when we do that bookkeeping move, it just becomes row 2 of \(X\).
X = cube.astype(np.float64).reshape(B, H * W).T # shape: (N, B)
N = X.shape[0]
print(f"Pixel matrix X: {X.shape}") # (94249, 210)In the real HYDICE scene, that bookkeeping step turns a 307 x 307 x 210 cube into a 94,249 x 210 matrix. Once the data are in this form, each pixel becomes one point in a 210-dimensional spectral space, and the methods below look for structure in that cloud of points.
PCA / SVD
Derivation
PCA looks for a small number of directions that explain most of the variation in the data. For a remote-sensing reader, one good way to think about it is this: if you had to summarize each 210-band spectrum with just a few spectral contrasts, which contrasts would matter most?
The plain-language version is:
- subtract the average spectrum
- rotate the data into the most informative spectral directions
- keep only the first few directions
Note
What PCA actually does to the matrix
- It subtracts one average spectrum from every row.
- It rotates the spectral axes into a new orthogonal basis ordered by variance.
- It lets you keep the first few directions and ignore the rest.
Mathematically, PCA is SVD applied to the mean-centered data. “Mean-centered” just means we subtract the average spectrum first:
\[X_c = X - \mathbf{1}\mu^T, \quad \mu = \frac{1}{N}\sum_{n=1}^{N} x_n\]
A centered spectrum is no longer “raw radiance.” It is “how this pixel differs from the scene average” at each wavelength. For a toy three-band example,
\[ \mu = \begin{bmatrix} 30 \\ 28 \\ 42 \end{bmatrix}, \qquad x_n = \begin{bmatrix} 26 \\ 32 \\ 51 \end{bmatrix}, \qquad x_n - \mu = \begin{bmatrix} -4 \\ 4 \\ 9 \end{bmatrix} \]
where those three entries correspond to 550 nm, 650 nm, and 850 nm.
That minus sign is the part that usually makes PCA feel strange at first. It does not mean negative light or negative material. It only means “below the average spectrum at this wavelength.”
Then approximate the centered matrix with a low-rank factorization:
\[X_c \approx ZV^T\]
Under the hood, this comes from the economy SVD:
\[X_c = U \Sigma V^T, \quad Z = U\Sigma\]
The three factors have a useful remote-sensing interpretation:
- \(V \in \mathbb{R}^{B \times K}\): spectral loading vectors, or wavelength patterns that capture strong variance
- \(Z \in \mathbb{R}^{N \times K}\): the per-pixel scores telling us where each pixel lands in the reduced PC space
- \(\Sigma \in \mathbb{R}^{K \times K}\): the strength of those patterns in the full SVD view
If you reshape one score column of \(Z\) back into image form, you get an eigenimage: a map showing where that spectral pattern is strong or weak. That is the exact bridge between the matrix factorization and the image. In scikit-learn, components_ stores rows of \(V^T\) and transform returns the score matrix \(Z\) (scikit-learn developers 2024b).
Code
Code
K = 12 # number of components to retain
pca = PCA(n_components=K, svd_solver="randomized", random_state=42)
Z = pca.fit_transform(X) # pixel scores, shape (N, K)
Vt = pca.components_ # spectral patterns, shape (K, B)
explained = pca.explained_variance_ratio_
# Eigenimages: reshape each score column back to spatial dimensions
eigenimages = Z.T.reshape(K, H, W) # shape: (K, H, W)
# Rank-K reconstruction and per-pixel L2 error
X_hat = pca.inverse_transform(Z)
error_map = np.linalg.norm(X - X_hat, axis=1).reshape(H, W)Scree plot and eigenimages
Code
fig, ax = plt.subplots(figsize=(6, 3.5))
ax.bar(range(1, K + 1), explained * 100, color="#4878CF", width=0.7)
ax.set_xlabel("Component")
ax.set_ylabel("Variance explained (%)")
ax.set_title("Scree plot: HYDICE Urban PCA")
plt.tight_layout()
plt.savefig(FIG_DIR / "scree.png", bbox_inches="tight")
plt.show()
fig2, axes2 = plt.subplots(2, 3, figsize=(12, 8))
for i, ax in enumerate(axes2.flat):
img = eigenimages[i]
vabs = np.percentile(np.abs(img), 99)
ax.imshow(img, cmap="RdBu_r", vmin=-vabs, vmax=vabs)
ax.set_title(f"PC {i+1} ({explained[i]*100:.1f}%)", fontsize=10)
ax.axis("off")
plt.suptitle("First 6 eigenimages", fontsize=12)
plt.tight_layout()
plt.savefig(FIG_DIR / "eigenimages.png", bbox_inches="tight")
plt.show()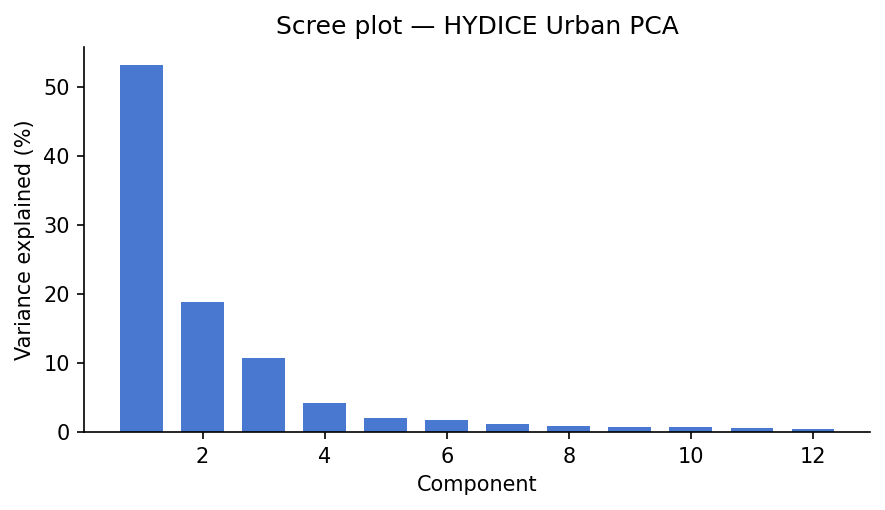
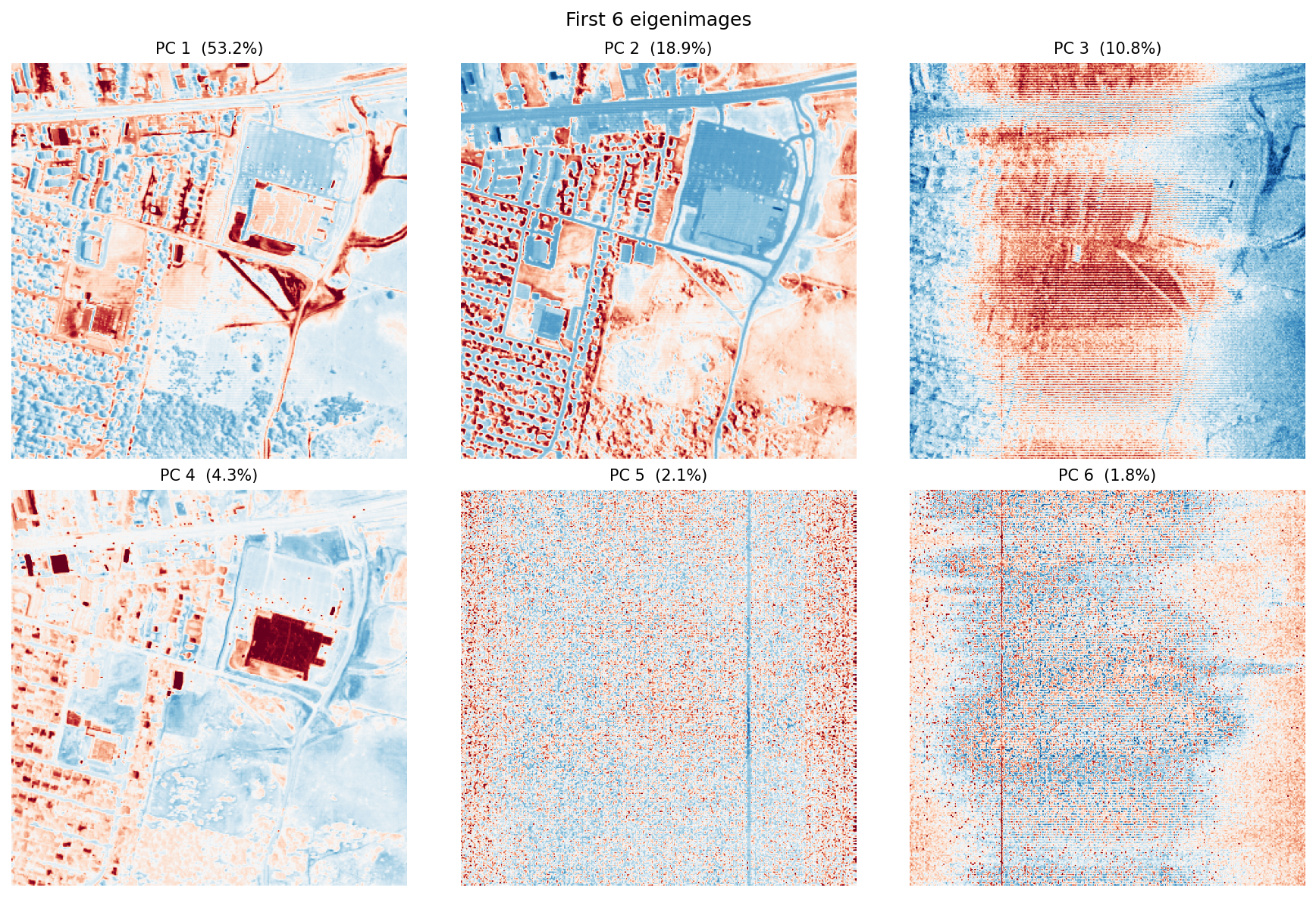
The scree plot answers “how many components are doing most of the work?” The eigenimages answer a different question: “where in the scene does each component matter?”
Usually, the first component captures broad scene brightness, because many wavelengths rise and fall together. The next few components often pick up real material contrasts, especially vegetation versus built surfaces or bright rooftops versus darker pavement. Later components tend to capture finer structure and, eventually, noise.
One important point: PCA values can be positive or negative. That is fine mathematically, but awkward physically. A negative PCA score does not mean “negative asphalt” or “negative grass.” It only means the pixel sits on one side of a mathematical axis instead of the other. That is why the next methods can be easier to interpret.
Reconstruction error map
Code
fig, ax = plt.subplots(figsize=(5.5, 5.5))
im = ax.imshow(error_map, cmap="inferno")
plt.colorbar(im, ax=ax, label="L2 reconstruction error (DN)")
ax.set_title(f"PCA reconstruction error (K = {K})", fontsize=11)
ax.axis("off")
plt.tight_layout()
plt.savefig(FIG_DIR / "pca_error.png", bbox_inches="tight")
plt.show()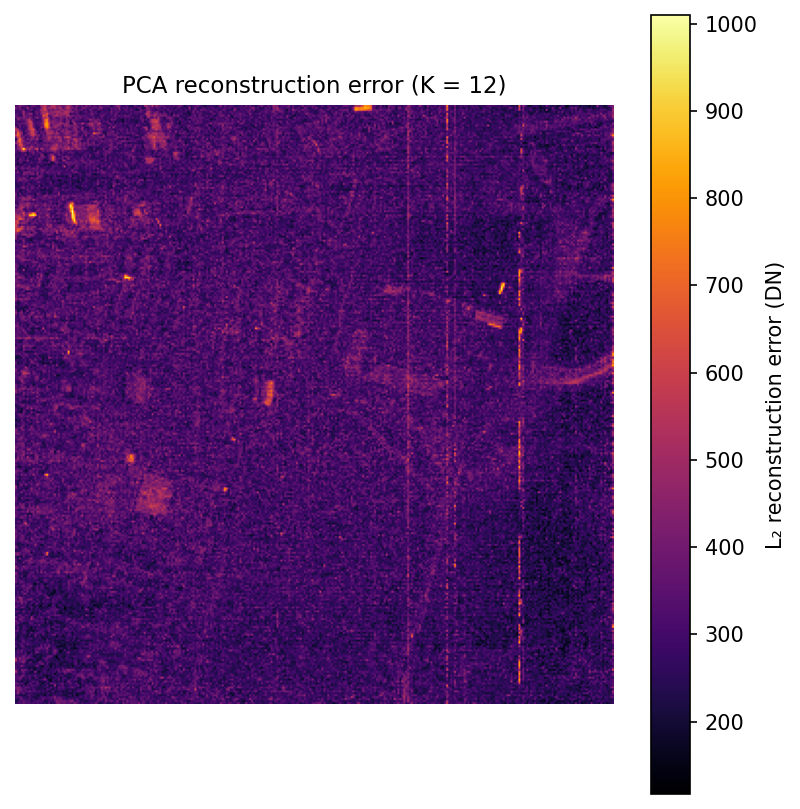
This map comes from a simple round trip: project each pixel into the first 12 principal components, reconstruct it back into 210 bands, and measure how much changed. Bright areas are pixels whose spectra are unusual or hard to summarize with just 12 components.
In practice, those bright spots often correspond to rare materials, shadows, standing water, vehicles, or strongly mixed pixels. That makes the error map a simple but useful anomaly detector.
Linear spectral unmixing
The linear mixing model
Now switch from compression to mixing.
The linear mixing model says that one pixel can be approximated as a weighted sum of a few pure material spectra, called endmembers (Plaza et al. 2009). For an urban scene at 2 m resolution, that is a reasonable first model: many pixels are mixtures of vegetation, pavement, roof, and shadow rather than perfectly pure targets.
If PCA is the contrast view, unmixing is the recipe view. The pixel is the dish, the endmembers are the ingredients, and the abundance vector tells us how much of each ingredient is present.
\[x_n \approx \sum_{p=1}^{P} s_{np} \, m_p = M s_n\]
At a single wavelength, the same recipe logic applies band by band. At 650 nm, for example,
\[x_{n,650} \approx s_{n1}m_{1,650} + s_{n2}m_{2,650} + \cdots + s_{nP}m_{P,650}\]
So the matrix equation is not doing anything mysterious. It is just applying the same weighted-sum idea at every wavelength at once.
In matrix form for all pixels: \(X \approx SM^T\), where \(M \in \mathbb{R}^{B \times P}\) is the endmember matrix and \(S \in \mathbb{R}^{N \times P}\) contains per-pixel abundance vectors.
This model is only an approximation, but it is a useful one. At 2 m resolution, many pixels cover more than one surface type, so “unmixing” means estimating the fractions of those hidden ingredients.
An illustrative toy abundance vector might look like this:
\[ s_n = \begin{bmatrix} 0.55 \\ 0.25 \\ 0.15 \\ 0.05 \end{bmatrix}, \qquad \text{ordered as } (\text{asphalt}, \text{grass}, \text{rooftop}, \text{trees}) \]
That means “this pixel looks mostly like asphalt, with some vegetation and a little roof and tree signal mixed in.”
Note
What unmixing actually does to the matrix
- It keeps the endmember matrix \(M\) fixed.
- It solves for one abundance vector \(s_n\) per pixel.
- It uses the residual to tell you where your ingredient list is incomplete.
Try a toy mixed pixel
This is the same idea in playable form. The sliders below control the amounts of four toy endmembers. The app normalizes them to sum to one, then redraws the mixed spectrum. The point is not physical realism. The point is to make the “pixel as recipe” idea feel concrete.
45%
25%
20%
10%
Asphalt
Grass
Rooftop
Trees
Mixture
The mixture line is the weighted sum of the four toy spectra. This is the intuition behind linear unmixing before any solver enters the picture.
Two physical constraints on the abundance vector \(s_n\):
- Abundance nonnegativity (ANC): \(s_n \geq 0\), you can’t have a negative fraction of a material
- Abundance sum-to-one (ASC): \(\mathbf{1}^T s_n = 1\), the fractions must add up
Together, those constraints make the weights behave like fractions. The optimization problem per pixel is:
\[s_n^* = \arg\min_{s \,\in\, \Delta^{P-1}} \|x_n - Ms\|_2^2\]
Once \(M\) is fixed, this is a well-behaved optimization problem that returns one abundance vector per pixel (Heinz and Chang 2001).
A toy example of why the constraints matter:
| Solver | Asphalt | Grass | Roof | Interpretation |
|---|---|---|---|---|
| Unconstrained least squares | 1.08 | -0.11 | 0.03 | Algebraically possible, physically nonsense |
| FCLS | 0.97 | 0.00 | 0.03 | Readable as fractions |
Endmember selection
Before we can solve for fractions, we need example spectra for the pure materials.
In a full remote-sensing workflow, you might estimate those endmembers automatically with algorithms such as N-FINDR or vertex component analysis. For a tutorial, hand-picking a few obvious pixels is easier to follow: choose one pixel that looks like road, one that looks like grass, one rooftop, and one tree patch.
# Hand-picked pixel coordinates (row, col)
endmember_pixels = {
"Asphalt": (200, 120),
"Grass": (80, 200),
"Rooftop": (150, 50),
"Trees": (50, 150),
}
P = len(endmember_pixels)
M = np.zeros((B, P))
for i, (name, (r, c)) in enumerate(endmember_pixels.items()):
M[:, i] = cube[:, r, c].astype(float)
fig, ax = plt.subplots(figsize=(8, 4))
for i, name in enumerate(endmember_pixels):
ax.plot(wavelengths, M[:, i], label=name, linewidth=1.5)
ax.set_xlabel("Wavelength (nm)")
ax.set_ylabel("Radiance (DN)")
ax.set_title("Endmember spectra")
ax.legend(frameon=False, fontsize=9)
plt.tight_layout()
plt.savefig(FIG_DIR / "endmembers.png", bbox_inches="tight")
plt.show()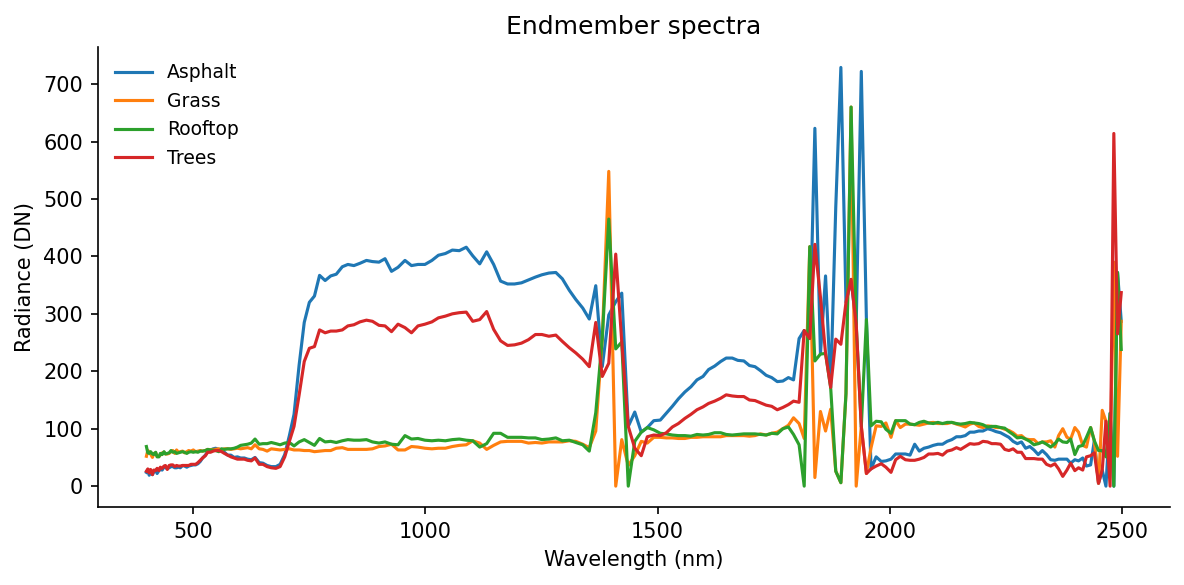
These four curves are not “the truth.” They are a small hand-built library. If one important material is missing, the residual map will tell on us later.
Solving for abundances: FCLS
Now we solve for the fractions in each pixel.
We use fully constrained least squares (FCLS). The goal is to estimate the nonnegative abundance vector that best reconstructs the observed spectrum while also forcing the abundances to sum to one. The implementation below uses a common NNLS-based trick from Heinz and Chang (2001).
Code
def fcls(M: np.ndarray, y: np.ndarray, delta: float = 100.0) -> np.ndarray:
"""Fully constrained least squares (ANC + ASC).
Embeds the sum-to-one constraint by augmenting [M; delta*1^T] @ s = [y; delta],
solves via NNLS (enforcing ANC), then normalizes to ensure sum(s) = 1.
Parameters
----------
M : (B, P) endmember matrix
y : (B,) pixel spectrum
delta : scaling factor for the ASC constraint row (larger = stricter enforcement)
"""
M_aug = np.vstack([M, delta * np.ones((1, M.shape[1]))])
y_aug = np.append(y, delta)
s, _ = nnls(M_aug, y_aug)
total = s.sum()
if total > 1e-10:
s /= total
return s
# Solve per pixel
S = np.zeros((N, P))
for n in range(N):
S[n] = fcls(M, X[n])
# Reshape abundance maps to (P, H, W)
abundance_maps = S.T.reshape(P, H, W)
# Per-pixel residual: ||y_n - M s_n||
residual = np.linalg.norm(X - S @ M.T, axis=1).reshape(H, W)
Note
The loop above is easy to read, but not especially fast. For HYDICE at 307 x 307 pixels it is still manageable. For much larger scenes, you would usually parallelize it or move to a more specialized solver.
Code
names = list(endmember_pixels.keys())
cmaps = ["Reds", "Greens", "Oranges", "YlGn"]
fig, axes = plt.subplots(1, P + 1, figsize=(16, 4))
for i, (name, cmap) in enumerate(zip(names, cmaps)):
axes[i].imshow(abundance_maps[i], cmap=cmap, vmin=0, vmax=1)
axes[i].set_title(name, fontsize=10)
axes[i].axis("off")
im = axes[-1].imshow(residual, cmap="inferno")
plt.colorbar(im, ax=axes[-1], label="Residual (DN)")
axes[-1].set_title("Residual", fontsize=10)
axes[-1].axis("off")
plt.suptitle("FCLS abundance maps + unmixing residual", fontsize=12)
plt.tight_layout()
plt.savefig(FIG_DIR / "abundance_maps.png", bbox_inches="tight")
plt.show()
The residual map tells you where the chosen endmembers are not enough. Bright residuals often mean “there is something here that the current material library cannot explain well,” such as shadow, water, or bare soil.
Compared with PCA, these abundance maps are easier to explain. Each one answers a direct question like: “Where in the scene does this ingredient seem common?” The trade-off is that the answer depends heavily on the endmembers you chose.
NMF
NMF asks a similar question to unmixing, but with less supervision: can we factor \(X\) into two nonnegative matrices without telling the model in advance what the materials are?
The easiest mental picture is: learn the ingredients and the ingredient amounts at the same time.
Note
What NMF actually does to the matrix
- It learns the spectral ingredients and their weights at the same time.
- It keeps both factors nonnegative, so components can add but not cancel.
- It trades physical constraints for exploratory flexibility.
\[X \approx WH, \quad W \in \mathbb{R}_{\geq 0}^{N \times K}, \; H \in \mathbb{R}_{\geq 0}^{K \times B}\]
The objective (squared Frobenius norm) is:
\[\min_{W,\, H\, \geq\, 0} \;\frac{1}{2}\|X - WH\|_F^2\]
Rows of \(H\) are learned spectral patterns. Each row of \(W\) tells us how strongly one pixel uses those patterns, and each column of \(W\) becomes a spatial weight map when reshaped back into image form. Unlike PCA, NMF does not allow negative values, and unlike unmixing, it does not require the weights to sum to one.
The main idea from Lee and Seung (1999) is simple: nonnegative parts can only add, not cancel each other out. That often makes the learned components easier to read. PCA can produce positive-negative contrast patterns. NMF tends to produce parts that look more like material pieces of the scene.
The downside is that NMF is not unique. Different initial guesses can lead to somewhat different answers. Using nndsvda gives the algorithm a stable starting point and usually leads to cleaner results (scikit-learn developers 2024a).
| Method | Spectral ingredients | Weight rule |
|---|---|---|
| Unmixing | supplied by you | nonnegative and sums to one |
| NMF | learned from the data | nonnegative only |
Code
K_nmf = 6
nmf = NMF(
n_components=K_nmf,
init="nndsvda", # deterministic SVD-based initialization
solver="mu", # multiplicative updates (Lee & Seung)
beta_loss="frobenius",
random_state=42,
max_iter=500,
)
W_nmf = nmf.fit_transform(X) # pixel weights, shape (N, K_nmf)
H_nmf = nmf.components_ # component spectra, shape (K_nmf, B)
nmf_maps = W_nmf.T.reshape(K_nmf, H, W)
fig, ax = plt.subplots(figsize=(9, 4))
for k in range(K_nmf):
ax.plot(wavelengths, H_nmf[k], label=f"Component {k+1}", linewidth=1.5)
ax.set_xlabel("Wavelength (nm)")
ax.set_ylabel("Learned basis value")
ax.set_title("NMF component spectra")
ax.legend(frameon=False, fontsize=9, ncol=2)
plt.tight_layout()
plt.savefig(FIG_DIR / "nmf_spectra.png", bbox_inches="tight")
plt.show()
fig2, axes2 = plt.subplots(2, 3, figsize=(12, 8))
for k, ax in enumerate(axes2.flat):
ax.imshow(nmf_maps[k], cmap="viridis")
ax.set_title(f"NMF component {k+1}", fontsize=10)
ax.axis("off")
plt.suptitle("NMF spatial weight maps", fontsize=12)
plt.tight_layout()
plt.savefig(FIG_DIR / "nmf_maps.png", bbox_inches="tight")
plt.show()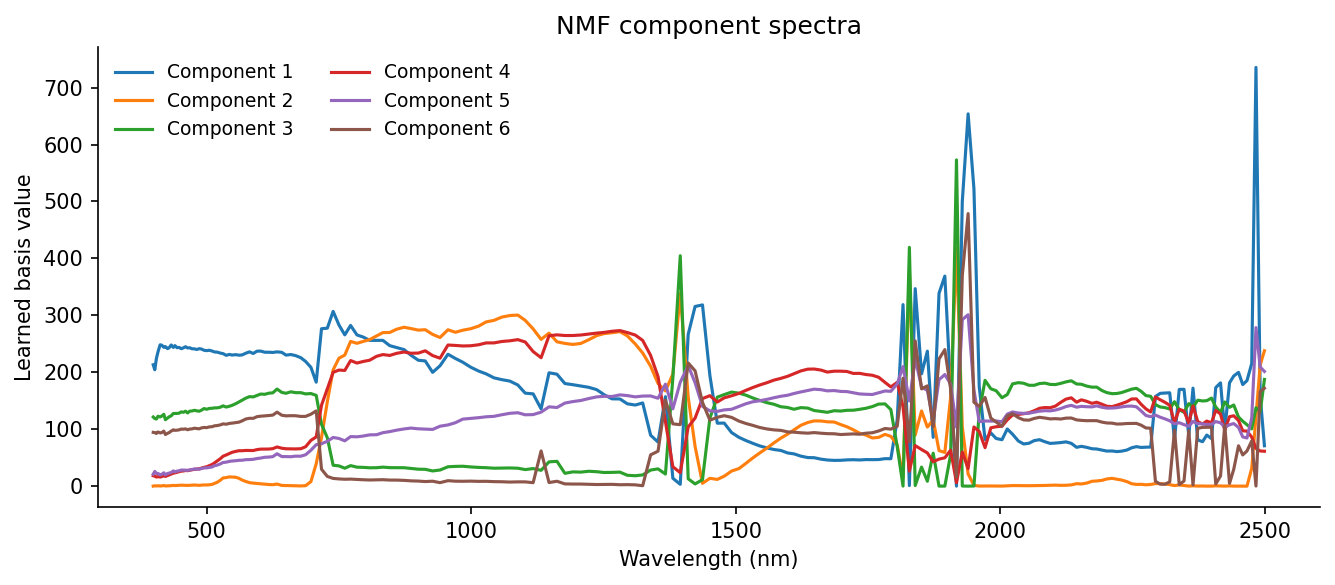

Where PCA gives contrast axes, NMF gives positive-only parts. Those parts are not guaranteed to be true materials, but they often look material-like enough to be useful. In practice, NMF is good for exploration when you do not yet know the right endmembers, while linear unmixing is better when you do know them and want physically interpretable fractions.
What These Methods Are Actually For
The cheap version of this section would be: classical methods are old, deep learning is newer, use deep learning when you can. I do not think that is very helpful.
The more honest version is that these methods answer different questions.
| If your real goal is… | Best first move | Why |
|---|---|---|
| Understand what is varying in the cube | PCA | Fast global structure, good for QA and anomaly screening |
| Estimate subpixel composition with plausible materials | Linear unmixing | Gives fractions plus a residual you can inspect |
| Explore additive parts before you trust a library | NMF | Learns basis spectra directly from the scene |
| Predict classes, detect targets, or segment with labels | Supervised ML or deep learning | Optimizes prediction rather than interpretation |
| Capture nonlinear spectral-spatial patterns | Deep learning | Uses context and nonlinearities the linear methods cannot |
Recent reviews are still useful here, but mostly as a reality check. They show that the field has moved strongly toward spectral-spatial deep models for tasks like crop mapping, denoising, onboard triage, and classification, while also repeating the same constraints over and over: labels are expensive, compute is finite, and interpretability does not come for free (Ghasemi et al. 2025; Bourriz et al. 2025).
What deep models genuinely add
Deep models can learn nonlinear relationships and spatial context that PCA, FCLS, and NMF simply do not model. That matters when neighboring pixels help disambiguate a target, when the decision boundary is not linear, or when the real goal is predictive accuracy rather than interpretability.
What I would not let them skip
Even if the eventual solution is a spectral-spatial neural network, I would still want to know:
- what the spectra look like before training
- whether the radiometry is trustworthy
- whether the scene is dominated by a few materials or many mixed ones
- where the weird pixels are
- whether a simpler baseline already explains most of the structure
That is what the classical methods are buying you. They are not just old alternatives. They are how you learn what kind of problem you have.
The workflow that feels honest to me
- Look at the cube as an image and as spectra.
- Use PCA to understand dominant variance and obvious outliers.
- Use unmixing or NMF to ask whether the scene reads more clearly as fractions or as learned parts.
- Only then decide whether the task actually wants a predictive model.
That is why I did not want to skip straight to “here is a transformer.” A model can be impressive and still leave you with very little intuition about what it learned.
Exporting products
All three methods produce spatial outputs worth saving. HYDICE Urban does not include geospatial metadata such as a CRS or geotransform, so .npy files are a simple and honest export format here. For georeferenced datasets, you would usually write GeoTIFFs instead:
Code
derived = Path("data/derived")
derived.mkdir(exist_ok=True)
# Save as .npy, HYDICE Urban has no CRS or geotransform, so plain arrays are more honest
# than an empty GeoTIFF. Each array is (layers, H, W), float32.
np.save(derived / "eigenimages.npy", eigenimages.astype(np.float32))
np.save(derived / "abundances.npy", abundance_maps.astype(np.float32))
np.save(derived / "nmf_maps.npy", nmf_maps.astype(np.float32))
np.save(derived / "wavelengths.npy", wavelengths)
print("Saved:", [str(p) for p in sorted(derived.glob("*.npy"))])Where this fits in a real pipeline
The analysis above sits in the middle of a larger hyperspectral workflow. One thing I had to keep reminding myself while learning this is that decomposition is not the whole pipeline. In a production setting, you would usually do several preprocessing steps before running PCA, unmixing, or NMF:
| Demo step | Production analogue | Why it matters |
|---|---|---|
| Load ENVI cube, parse wavelengths | Data ingest, metadata validation | Wrong wavelength labels corrupt every downstream result |
| Radiance discussion | Radiometric calibration, unit consistency | Decompositions are only cross-scene comparable when inputs share a radiometric convention |
| Spatial subset / windowed read | Tiling, chunked processing, distributed compute | Windowed I/O and chunk sizing are core scaling tactics for cubes that exceed RAM |
| PCA eigenimages + error map | QA, compression, anomaly flagging | Error maps surface model mismatch and flag rare materials |
| FCLS abundance maps | Subpixel material estimation | ANC + ASC encode physical meaning; residuals guide endmember library iteration |
| NMF component maps | Blind source separation, interpretable bases | Nonnegativity improves spectral factor interpretability without manual endmember selection |
| Export derived products | .npy here (no geospatial metadata); GeoTIFF/COG for georeferenced datasets |
Product generation, GIS integration |
Real pipelines usually include radiometric calibration, geometric correction, and atmospheric correction before this stage (Plaza et al. 2009). This post skips those steps because the goal is to teach the decomposition ideas clearly, not to build a full operational workflow.
If You Only Remember Three Things
- A hyperspectral pixel is not just a color. It is a curve.
- PCA, unmixing, and NMF are three different ways of asking what that curve is made of or how it varies.
- The most useful question is not “which method is best?” but “what kind of answer do I need from this cube?”
Reproducibility
- Random seeds:
random_state=42for PCA and NMF ensures deterministic results across runs. - All figures use the full 307 x 307 scene with no extra spatial cropping, so re-renders should match exactly.
- Freeze your environment:
conda env export > environment.ymloruv pip freeze > requirements.txt. - The dataset is freely available from ERDC (U.S. Army Engineer Research and Development Center 2004); record the access date and use the provided handle as a citation.
References
Bourriz, Mohamed, Hicham Hajji, Ahmed Laamrani, Nadir Elbouanani, Hamd Ait Abdelali, Francois Bourzeix, Ali El-Battay, Abdelhakim Amazirh, and Abdelghani Chehbouni. 2025. “Integration of Hyperspectral Imaging and AI Techniques for Crop Type Mapping: Present Status, Trends, and Challenges.” Remote Sensing 17 (9): 1574. https://doi.org/10.3390/rs17091574.
Ghasemi, Nafiseh, Jon Alvarez Justo, Marco Celesti, Laurent Despoisse, and Jens Nieke. 2025. “Onboard Processing of Hyperspectral Imagery: Deep Learning Advancements, Methodologies, Challenges, and Emerging Trends.” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing 18: 4780–90. https://doi.org/10.1109/JSTARS.2025.3527898.
Heinz, Daniel C., and Chein-I Chang. 2001. “Fully Constrained Least Squares Linear Spectral Mixture Analysis Method for Material Quantification in Hyperspectral Imagery.” IEEE Transactions on Geoscience and Remote Sensing 39 (3): 529–45. https://doi.org/10.1109/36.911111.
Jet Propulsion Laboratory. 1992. “AVIRIS Free Standard Data Products — Moffett Field Radiance.” NASA Jet Propulsion Laboratory. https://aviris.jpl.nasa.gov/data/free_data.html.
Lee, Daniel D., and H. Sebastian Seung. 1999. “Learning the Parts of Objects by Non-Negative Matrix Factorization.” Nature 401: 788–91. https://doi.org/10.1038/44565.
NASA Ocean Biology Processing Group. 2023. “SeaDAS — Radiance to Reflectance Conversion Documentation.” NASA Goddard Space Flight Center. https://seadas.gsfc.nasa.gov/.
Plaza, Antonio, Jon Atli Benediktsson, Joseph W. Boardman, Jason Brazile, Lorenzo Bruzzone, Gustavo Camps-Valls, Jocelyn Chanussot, et al. 2009. “Recent Advances in Techniques for Hyperspectral Image Processing.” Remote Sensing of Environment 113: S110–22. https://doi.org/10.1016/j.rse.2009.06.009.
scikit-learn developers. 2024a. “Sklearn.decomposition.NMF — Scikit-Learn Documentation.” https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.NMF.html.
———. 2024b. “Sklearn.decomposition.PCA — Scikit-Learn Documentation.” https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html.
U.S. Army Engineer Research and Development Center. 2004. “HyperCube Hyperspectral Image Analysis Software — URBAN Sample Dataset.” U.S. Army ERDC. https://www.erdc.usace.army.mil/Media/Fact-Sheets/Fact-Sheet-Article-View/Article/610433/hypercube/.
Citation
BibTeX citation:
@online{miller2026,
author = {Miller, Emily},
title = {Hyperspectral {Hyperawareness}},
date = {2026-03-28},
url = {https://rellimylime.github.io/posts/hyperspectral-imaging},
langid = {en}
}
For attribution, please cite this work as:
Miller, Emily. 2026. “Hyperspectral Hyperawareness.” March
28, 2026. https://rellimylime.github.io/posts/hyperspectral-imaging.