# ── Setup ─────────────────────────────────────────────────────────────────────
library(tidyverse)
library(here)
library(patchwork)
library(scales)
library(sysfonts)
library(showtext)
library(ggtext)
# Raw files: CA Highway Patrol SWITRS database, crashes + parties CSVs (2024).
# Download portal: https://iswitrs.chp.ca.gov
# Cleaning, filtering to at-fault drivers, and joining the two files is
# documented in exploration.qmd. The processed file was saved there with:
# write_csv(crash_clean, here("data/processed/crash_clean.csv"))
crash_clean <- read_csv(here("data/processed/crash_clean.csv"),
show_col_types = FALSE)
# "rajdhani" is the family name used in all family = "rajdhani" calls below
font_add_google("Rajdhani", "rajdhani")
showtext_auto()
# ── Color palette ─────────────────────────────────────────────────────────────
PAL <- list(
plot_bg = "#07091E", # chart background - deep indigo
bg = "#0D0F28", # page background, used in myth 2 patchwork panel
alcohol = "#FF3333", # red - alcohol-impaired / danger
sober = "#4DB8FF", # blue - sober / safe
text_primary = "#FFFFFF", # titles
text_muted = "#7A8EBB", # subtitles
text_axis = "#A8BCD8", # axis labels
grid_line = "#1A2550" # grid lines
)
# ── Shared theme ──────────────────────────────────────────────────────────────
# Applied to all three charts; individual charts add overrides on top.
dashboard_theme <- theme_void() +
theme(
plot.background = element_rect(fill = PAL$plot_bg, color = NA),
panel.background = element_rect(fill = PAL$plot_bg, color = NA),
panel.grid.major.y = element_line(color = PAL$grid_line),
axis.text.x = element_text(
color = PAL$text_axis, size = 25, # large enough to read on polar clock face
face = "bold", family = "rajdhani"
),
plot.title = element_text(
color = PAL$text_primary, hjust = 0.5, # centered
face = "bold", family = "rajdhani",
size = 35, margin = margin(b = 2) # tight gap below title
),
plot.subtitle = element_text(
color = PAL$text_muted, hjust = 0.5, # centered
size = 20, family = "rajdhani",
margin = margin(t = 2, b = 6) # small top, more breathing room below
),
plot.margin = margin(10, 15, 8, 15) # top right bottom left
)
# ── Visualization 1: Myth 1 ───────────────────────────────────────────────────
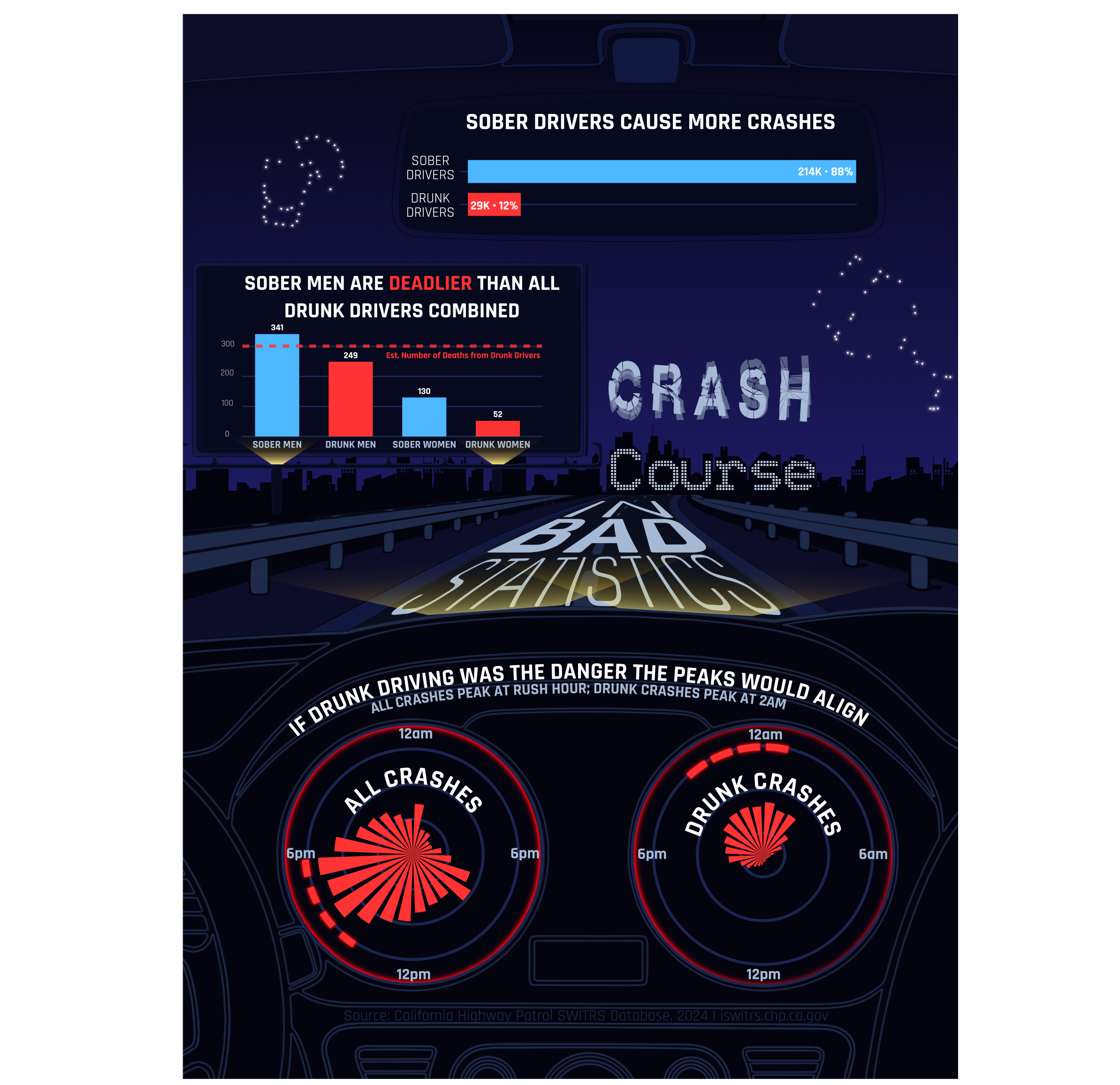
# "Sober Drivers Don't Cause Most Crashes"
# Shows raw crash counts by sobriety. Sober drivers account for ~88% of crashes.
# By reporting counts instead of rates, the chart makes sober driving look like
# the bigger danger - technically true, deliberately misleading.
fmt_n <- label_number(scale_cut = cut_short_scale())
myth1_data <- crash_clean |>
filter(!is.na(sobriety)) |>
distinct(collision_id, sobriety) |>
count(sobriety) |>
mutate(
pct = round(n / sum(n) * 100),
driver = if_else(sobriety == "No alcohol", "SOBER\nDRIVERS", "DRUNK\nDRIVERS"),
label = paste0(fmt_n(n), " \u00b7 ", pct, "% ")
)
ggplot(myth1_data, aes(x = n, y = reorder(driver, n), fill = sobriety)) +
geom_col(width = 0.7) + # narrower than default; breathing room between bars
geom_text(
aes(label = label),
hjust = 1.05, # flush against right edge of bar, inside
color = "white", family = "rajdhani", fontface = "bold", size = 6
) +
scale_fill_manual(
values = c("No alcohol" = PAL$sober, "Alcohol impaired" = PAL$alcohol),
guide = "none"
) +
scale_x_continuous(expand = expansion(mult = c(0.02, 0))) + # left padding
labs(
title = "SOBER DRIVERS CAUSE MORE CRASHES",
subtitle = "Raw crash counts \u00b7 CA SWITRS 2024",
x = NULL, y = NULL
) +
dashboard_theme +
theme(
axis.text.y = element_text(color = PAL$text_axis, size = 18, family = "rajdhani"),
axis.text.x = element_blank(),
panel.grid = element_blank()
)
ggsave("myth1.pdf")
# ── Visualization 2: Myth 2 ───────────────────────────────────────────────────
# "Drunk Driving Makes the Roads Dangerous for Everyone"
# Juxtaposes crash timing for all crashes (left, morning rush peak) against
# alcohol-impaired crashes (right, 2am peak - shown at 2.2x expanded y-scale
# to make the pattern look minor). The mismatch implies drunk driving can't be
# responsible for the most dangerous conditions.
all_crashes <- crash_clean |>
distinct(collision_id, hour) |>
count(hour)
alc_crashes <- crash_clean |>
filter(sobriety == "Alcohol impaired") |>
distinct(collision_id, hour) |>
count(hour)
# Peak-hour indicator ring positions (top 4 hours in each panel)
all_peaks <- all_crashes |>
slice_max(n, n = 4, with_ties = FALSE) |>
pull(hour)
alc_peaks <- alc_crashes |>
slice_max(n, n = 4, with_ties = FALSE) |>
pull(hour)
all_limit <- max(all_crashes$n, na.rm = TRUE) * 1.22
alc_limit <- max(alc_crashes$n, na.rm = TRUE) * 2.2
all_ring <- tibble(hour = all_peaks, ring_y = all_limit * 0.93)
alc_ring <- tibble(hour = alc_peaks, ring_y = alc_limit * 0.93)
all_ring_h <- all_limit * 0.06
alc_ring_h <- alc_limit * 0.06
# Extra margin + clip off so polar axis labels don't get chopped at panel edges
myth2_clock_theme <- theme(
panel.grid.major.y = element_line(color = PAL$grid_line, linewidth = 0.7),
plot.title = element_text(color = PAL$text_primary, hjust = 0.5, face = "bold", family = "rajdhani", size = 18),
plot.subtitle = element_text(color = PAL$text_muted, hjust = 0.5, family = "rajdhani", size = 12),
axis.text.x = element_text(
color = PAL$text_axis, size = 16, face = "bold", family = "rajdhani",
margin = margin(t = 4, r = 4, b = 4, l = 4)
),
plot.margin = margin(12, 28, 18, 28)
)
p_all <- ggplot(all_crashes, aes(x = factor(hour, levels = 0:23), y = n)) +
geom_col(width = 0.72, fill = PAL$alcohol) + # slight gap between clock segments
geom_tile(
data = all_ring,
inherit.aes = FALSE,
aes(x = factor(hour, levels = 0:23), y = ring_y),
fill = PAL$alcohol, alpha = 0.95, width = 0.6, height = all_ring_h
) +
coord_polar(clip = "off") +
scale_x_discrete(
breaks = c("0", "6", "12", "18"), # label quarter-hours only
labels = c("12am", "6am", "12pm", "6pm")
) +
scale_y_continuous(
limits = c(0, all_limit),
expand = expansion(mult = c(0, 0))
) +
labs(
title = "ALL CRASHES BY HOUR",
subtitle = "Morning commute is the deadliest window"
) +
dashboard_theme +
myth2_clock_theme
# Expanded y-axis so alcohol bars only reach ~45% of clock face,
# making the pattern look minor and clearly misaligned with the left chart
p_alc <- ggplot(alc_crashes, aes(x = factor(hour, levels = 0:23), y = n)) +
geom_col(width = 0.72, fill = PAL$alcohol) +
geom_tile(
data = alc_ring,
inherit.aes = FALSE,
aes(x = factor(hour, levels = 0:23), y = ring_y),
fill = PAL$alcohol, alpha = 0.95, width = 0.78, height = alc_ring_h
) +
coord_polar(clip = "off") +
scale_x_discrete(
breaks = c("0", "6", "12", "18"),
labels = c("12am", "6am", "12pm", "6pm")
) +
scale_y_continuous(
limits = c(0, alc_limit), # 2.2x makes bars fill ~45% of face
expand = expansion(mult = c(0, 0))
) +
labs(
title = "ALCOHOL-IMPAIRED CRASHES BY HOUR",
subtitle = "Fewer crashes -- and the peak doesn't match"
) +
dashboard_theme +
myth2_clock_theme
p_all + p_alc +
plot_annotation(
title = "IF DRUNK DRIVING CAUSED THE DANGER, THE PEAKS WOULD ALIGN",
theme = theme(
plot.title = element_text(
color = PAL$text_primary, hjust = 0.5, # centered over both panels
face = "bold", family = "rajdhani", size = 14
),
plot.background = element_rect(fill = PAL$bg, color = NA),
plot.margin = margin(4, 4, 4, 4)
)
) &
theme(
plot.background = element_rect(fill = PAL$plot_bg, color = NA),
panel.background = element_rect(fill = PAL$plot_bg, color = NA)
)
ggsave("myth2.pdf")
# ── Visualization 3: Myth 3 ───────────────────────────────────────────────────
# "Drunk Driving Is What's Killing Californians"
# Breaks down estimated deaths (crashes x fatality rate) by gender and sobriety.
# Sober men account for more estimated deaths than all drunk drivers combined.
# The dashed reference line marks the sum of estimated deaths across both drunk
# driver groups.
myth3_data <- crash_clean |>
filter(!is.na(sobriety), gender_code %in% c("M", "F")) |>
distinct(collision_id, gender_code, sobriety, fatal) |>
group_by(gender_code, sobriety) |>
summarize(
est_deaths = round(n() * mean(fatal, na.rm = TRUE)),
.groups = "drop"
) |>
mutate(
group_label = case_when(
gender_code == "M" & sobriety == "No alcohol" ~ "SOBER MEN",
gender_code == "M" & sobriety == "Alcohol impaired" ~ "DRUNK MEN",
gender_code == "F" & sobriety == "No alcohol" ~ "SOBER WOMEN",
gender_code == "F" & sobriety == "Alcohol impaired" ~ "DRUNK WOMEN"
),
group_label = factor(
group_label,
levels = c("SOBER MEN", "DRUNK MEN", "SOBER WOMEN", "DRUNK WOMEN")
)
)
# Sum of estimated deaths for drunk men + drunk women combined
all_drunk <- myth3_data |>
filter(sobriety == "Alcohol impaired") |>
pull(est_deaths) |>
sum()
ggplot(myth3_data, aes(x = group_label, y = est_deaths, fill = sobriety)) +
geom_col(width = 0.6) + # narrower columns; more whitespace between groups
geom_hline(
yintercept = all_drunk,
linetype = "dashed", color = PAL$alcohol, linewidth = 0.8, alpha = 0.8
) +
annotate(
"text",
x = 0.6, y = all_drunk - 18, # left of first bar, above reference line
label = paste0("Est. Number of Deaths from Drunk Drivers - Cumulative: ", all_drunk),
color = PAL$alcohol, hjust = -.95,
family = "rajdhani", size = 4.2
) +
geom_text(
aes(label = est_deaths),
vjust = -0.4, # just above bar top
family = "rajdhani", fontface = "bold", size = 4.5,
color = "white"
) +
expand_limits(y = max(myth3_data$est_deaths) * 1.2) + # 20% headroom for value labels
scale_fill_manual(
values = c("Alcohol impaired" = PAL$alcohol, "No alcohol" = PAL$sober),
guide = "none"
) +
labs(
title = "SOBER MEN ARE <span style='color:#FF3333'>DEADLIER</span><br>THAN ALL DRUNK DRIVERS COMBINED",
subtitle = "Estimated deaths = crashes \u00d7 fatality rate, by gender and sobriety",
x = NULL,
y = "Estimated deaths"
) +
dashboard_theme +
theme(
axis.text.x = element_text(color = PAL$text_axis, size = 14, family = "rajdhani"),
axis.text.y = element_text(color = PAL$text_axis, size = 14, family = "rajdhani"),
panel.grid.major.y = element_line(color = PAL$grid_line),
panel.grid.major.x = element_blank(),
plot.title = element_markdown( # allows HTML color span in title
color = PAL$text_primary, hjust = 0.5,
face = "bold", family = "rajdhani",
size = 35, margin = margin(b = 2)
)
)
ggsave("myth3.pdf")